
A PM's Guide to AI Agent Architecture: Why Capability Doesn't Equal Adoption
A complete guide to agent architecture, orchestration patterns, trust strategies, and adoption plans for PMs building AI agents.

Last week, I was talking to a PM who'd in the recent months shipped their AI agent. The metrics looked great: 89% accuracy, sub-second respond times, positive user feedback in surveys. But users were abandoning the agent after their first real problem, like a user with both a billing dispute and a locked account.
"Our agent could handle routine requests perfectly, but when faced with complex issues, users would try once, get frustrated, and immediately ask for a human."
This pattern is observed across every product team that focuses on making their agents "smarter" when the real challenge is making architectural decisions that shape how users experience and begin to trust the agent.
In this post, I'm going to walk you through the different layers of AI agent architecture. How your product decisions determine whether users trust your agent or abandon it. By the end of this, you'll understand why some agents feel "magical" while others feel "frustrating" and more importantly, how PMs should architect for the magical experience.
We'll use a concrete customer support agent example throughout, so you can see exactly how each architectural choice plays out in practice. We’ll also see why the counterintuitive approach to trust (hint: it's not about being right more often) actually works better for user adoption.
Let's say you're building a customer support agent
You're the PM building an agent that helps users with account issues - password resets, billing questions, plan changes. Seems straightforward, right?

But when a user says "I can't access my account and my subscription seems wrong" what should happen?
Scenario A: Your agent immediately starts checking systems. It looks up the account, identifies that the password was reset yesterday but the email never arrived, discovers a billing issue that downgraded the plan, explains exactly what happened, and offers to fix both issues with one click.
Scenario B: Your agent asks clarifying questions. "When did you last successfully log in? What error message do you see? Can you tell me more about the subscription issue?" After gathering info, it says "Let me escalate you to a human who can check your account and billing."
Same user request. Same underlying systems. Completely different products.
The Four Layers Where Your Product Decisions Live
Think of agent architecture like a stack where each layer represents a product decision you have to make.
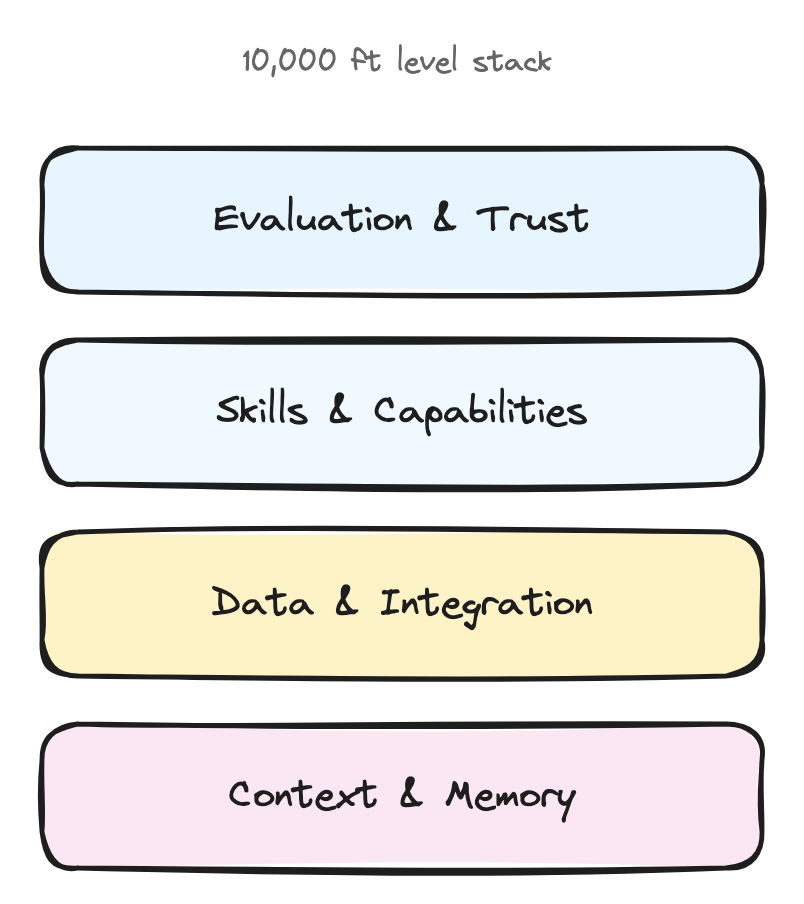
Layer 1: Context & Memory (What does your agent remember?)
The Decision: How much should your agent remember, and for how long?
This isn't just technical storage - it's about creating the illusion of understanding. Your agent's memory determines whether it feels like talking to a robot or a knowledgeable colleague.
For our support agent: Do you store just the current conversation, or the customer's entire support history? Their product usage patterns? Previous complaints?
Types of memory to consider:
Session memory: Current conversation ("You mentioned billing issues earlier...")
Customer memory: Past interactions across sessions ("Last month you had a similar issue with...")
Behavioral memory: Usage patterns ("I notice you typically use our mobile app...")
Contextual memory: Current account state, active subscriptions, recent activity
The more your agent remembers, the more it can anticipate needs rather than just react to questions. Each layer of memory makes responses more intelligent but increases complexity and cost.
Layer 2: Data & Integration (How deep do you go?)
The Decision: Which systems should your agent connect to, and what level of access should it have?
The deeper your agent connects to user workflows and existing systems, the harder it becomes for users to switch. This layer determines whether you're a tool or a platform.
For our support agent: Should it integrate with just your Stripe’s billing system, or also your Salesforce CRM, ZenDesk ticketing system , user database, and audit logs? Each integration makes the agent more useful but also creates more potential failure points - think API rate limits, authentication challenges, and system downtime.
Here's what's interesting - Most of us get stuck trying to integrate with everything at once. But the most successful agents started with just 2-3 key integrations and added more based on what users actually asked for.
Layer 3: Skills & Capabilities (What makes you different?)
The Decision: Which specific capabilities should your agent have, and how deep should they go?
Your skills layer is where you win or lose against competitors. It's not about having the most features - it's about having the right capabilities that create user dependency.
For our support agent: Should it only read account information, or should it also modify billing, reset passwords, and change plan settings? Each additional skill increases user value but also increases complexity and risk.

Implementation note: Tools like MCP (Model Context Protocol) are making it much easier to build and share skills across different agents, rather than rebuilding capabilities from scratch.
Layer 4: Evaluation & Trust (How do users know what to expect?)
The Decision: How do you measure success and communicate agent limitations to users?
This layer determines whether users develop confidence in your agent or abandon it after the first mistake. It's not just about being accurate - it's about being trustworthy.
For our support agent: Do you show confidence scores ("I'm 85% confident this will fix your issue")? Do you explain your reasoning ("I checked three systems and found...")? Do you always confirm before taking actions ("Should I reset your password now?")? Each choice affects how users perceive reliability.
Trust strategies to consider:
Confidence indicators: "I'm confident about your account status, but let me double-check the billing details"
Reasoning transparency: "I found two failed login attempts and an expired payment method"
Graceful boundaries: "This looks like a complex billing issue - let me connect you with our billing specialist who has access to more tools"
Confirmation patterns: When to ask permission vs. when to act and explain
The counterintuitive insight: users trust agents more when they admit uncertainty than when they confidently make mistakes.
So how do you actually architect an agent?
Okay, so you understand the layers. Now comes the practical question that every PM asks: "How do I actually implement this? How does the agent talk to the skills? How do skills access data? How does evaluation happen while users are waiting?"
Your orchestration choice determines everything about your development experience, your debugging process, and your ability to iterate quickly.

Lets walk through the main approaches, and I'll be honest about when each one works and when it becomes a nightmare.
1. Single-Agent Architecture (Start Here)
Everything happens in one agent's context.
For our support agent: When the user says "I can't access my account," one agent handles it all - checking account status, identifying billing issues, explaining what happened, offering solutions.
Why this works: Simple to build, easy to debug, predictable costs. You know exactly what your agent can and can't do.
Why it doesn't: Can get expensive with complex requests since you're loading full context every time. Hard to optimize specific parts.
Most teams start here, and honestly, many never need to move beyond it. If you're debating between this and something more complex, start here.
2. Skill-Based Architecture (When You Need Efficiency)
You have a router that figures out what the user needs, then hands off to specialized skills.
For our support agent: Router realizes this is an account access issue and routes to the `LoginSkill`. If the LoginSkill discovers it's actually a billing problem, it hands off to `BillingSkill`.
Real example flow:
User: "I can't log in"
Router → LoginSkill
LoginSkill checks: Account exists ✓, Password correct ✗, Billing status... wait, subscription expired
LoginSkill → BillingSkill: "Handle expired subscription for user123"
BillingSkill handles renewal process
Why this works: More efficient - you can use cheaper models for simple skills, expensive models for complex reasoning. Each skill can be optimized independently.
Why it doesn't: Coordination between skills gets tricky fast. Who decides when to hand off? How do skills share context?
Here's where MCP really helps - it standardizes how skills expose their capabilities, so your router knows what each skill can do without manually maintaining that mapping.
3. Workflow-Based Architecture (Enterprise Favorite)
You predefine step-by-step processes for common scenarios. Think LangGraph, CrewAI, AutoGen, N8N, etc.
For our support agent: "Account access problem" triggers a workflow:
Check account status
If locked, check failed login attempts
If too many failures, check billing status
If billing issue, route to payment recovery
If not billing, route to password reset
Why this works: Everything is predictable and auditable. Perfect for compliance-heavy industries. Easy to optimize each step.
Why it doesn't: When users have weird edge cases that don't fit your predefined workflows, you're stuck. Feels rigid to users.
4. Collaborative Architecture (The Future?)
Multiple specialized agents work together using A2A (agent-to-agent) protocols.
The vision: Your agent discovers that another company's agent can help with issues, automatically establishes a secure connection, and collaborates to solve the customer's problem. Think a booking.com agent interacting with an American Airlines agent!
For our support agent: `AuthenticationAgent` handles login issues, `BillingAgent` handles payment problems, `CommunicationAgent` manages user interaction. They coordinate through standardized protocols to solve complex problems.
Reality check: This sounds amazing but introduces complexity around security, billing, trust, and reliability that most companies aren't ready for. We're still figuring out the standards.
This can produce amazing results for sophisticated scenarios, but debugging multi-agent conversations is genuinely hard. When something goes wrong, figuring out which agent made the mistake and why is like detective work.

Here's the thing: start simple. Single-agent architecture handles way more use cases than you think. Add complexity only when you hit real limitations, not imaginary ones.
But here's what's interesting - even with the perfect architecture, your agent can still fail if users don't trust it. That brings us to the most counterintuitive lesson about building agents.
The trust thing that everyone gets wrong
Here's something counterintuitive: Users don't trust agents that are right all the time. They trust agents that are honest about when they might be wrong.
Think about it from the user's perspective. Your support agent confidently says "I've reset your password and updated your billing address." User thinks "great!" Then they try to log in and... it doesn't work. Now they don't just have a technical problem - they have a trust problem.
Compare that to an agent that says "I think I found the issue with your account. I'm 80% confident this will fix it. I'm going to reset your password and update your billing address. If this doesn't work, I'll immediately escalate to a human who can dive deeper."
Same technical capability. Completely different user experience.
Building trusted agents requires focus on three things:
Confidence calibration: When your agent says it's 60% confident, it should be right about 60% of the time. Not 90%, not 30%. Actual 60%.
Reasoning transparency: Users want to see the agent's work. "I checked your account status (active), billing history (payment failed yesterday), and login attempts (locked after 3 failed attempts). The issue seems to be..."
Graceful escalation: When your agent hits its limits, how does it hand off? A smooth transition to a human with full context is much better than "I can't help with that."
A lot of times we obsess over making agents more accurate, when what users actually want was more transparency about the agent's limitations.
What's Coming Next
In Part 2, I'll dive deeper into the autonomy decisions that keep most PMs up at night. How much independence should you give your agent? When should it ask for permission vs forgiveness? How do you balance automation with user control?
We'll also walk through the governance concerns that actually matter in practice - not just theoretical security issues, but the real implementation challenges that can make or break your launch timeline.
Thanks for sharing your thoughts. I am curious how does Skill Based Architecture defer from Single Agent Architecture. In single agent architecture, the agent has access to multiple skills which seems very similar to Skill Based Architecture.